




1. Pendahuluan [kembali]
Sistem monitoring dan kontrol hidroponik yang dirancang memanfaatkan berbagai sensor seperti sensor pH untuk memantau keasaman larutan nutrisi, sensor TDS/EC untuk mengukur konsentrasi nutrisi, sensor suhu air, serta sensor kelembaban dan suhu lingkungan. Data dari seluruh sensor ini digunakan sebagai dasar pengambilan keputusan otomatis, misalnya mengaktifkan pompa nutrisi saat kadar TDS menurun, menyalakan aerator untuk menjaga kadar oksigen dalam larutan, atau menyesuaikan sistem pendingin/kipas saat suhu lingkungan terlalu tinggi. Dengan integrasi ini, tanaman dapat memperoleh kondisi tumbuh yang konsisten, stabil, dan lebih produktif.
Selain fitur utama pengelolaan nutrisi dan lingkungan, sistem ini juga dilengkapi dengan fungsi keamanan serta mekanisme peringatan dini. Jika terdeteksi kondisi berbahaya seperti penurunan drastis pH, kegagalan pompa air, atau suhu air yang melebihi batas aman, sistem hazard otomatis akan aktif untuk menghentikan proses tertentu dan memberi notifikasi peringatan. Dengan dukungan teknologi sensor dan aktuator yang saling terhubung, sistem hidroponik ini mampu beroperasi lebih aman, efisien, dan minim intervensi manual. Teknologi ini diharapkan menjadi solusi inovatif bagi petani modern dalam meningkatkan produktivitas, menghemat sumber daya, serta menjaga kualitas tanaman di era pertanian cerdas.
2. Tujuan [kembali]
- Menyelesaikan tugas besar mata kuliah Sensor yang diberikan oleh Bapak Dr. Darwison, M. T selaku dosen pengampu
- Memahami konsep dasar dan pengaplikasian berbagai sensor yang sesuai dengan hidroponik pokcoy
- Menentukan dan merangkai rangkaian dasar sistem monitoring dan kontrol hiduponik pokcoy
- Menganalisa dan menyimpulkan hasil simulasi rangkaian yang telah dirancang
3. Alat dan Bahan [kembali]

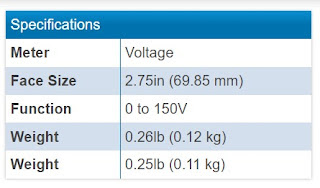
Berikut adalah Spesifikasi dan keterangan Probe DC Volemeter


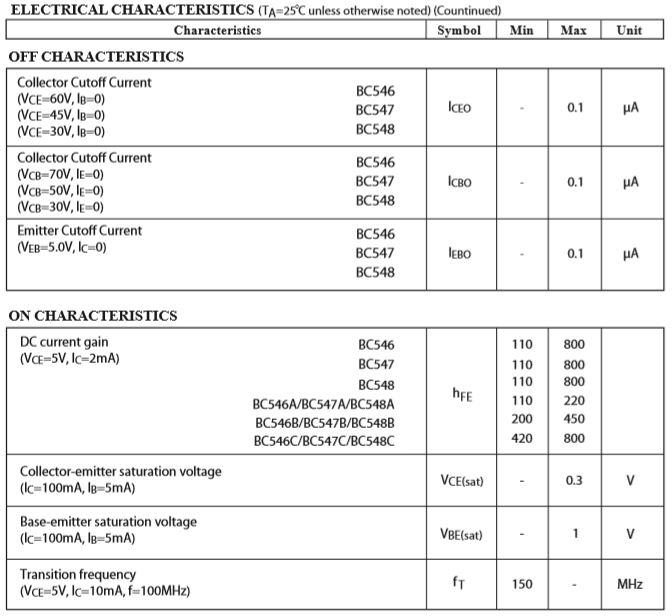
Transistor merupakan alat semikonduktor yang dapat digunakan sebagai penguat sinyal, pemutus atau penyambung sinyal (switching), stabilisasi tegangan, dan fungsi lainnya. Transistor memiliki 3 kaki elektroda, yaitu basis, kolektor, dan emitor. Pada rangkaian kali ini digunakan transistor BC547 bertipe NPN.
Spesifikasi dan konfigurasi pin:


2) Resistor

Resistor merupakan komponen elektronika pasif yang berfungsi untuk membatasi arus yang mengalir pada suatu rangkaian dan berfungsi sebagai terminal antara dua komponen elektronika. Tegangan pada suatu resistor sebanding dengan arus yang melewatinya.
Spesifikasi:


3) Dioda


5) Resistor

Resistor adalah komponen elektronika pasif yang memiliki nilai resistansi atau hambatan tertentu yang berfungsi untuk membatasi dan mengatur arus listrik dalam suatu rangkaian elektronika. Satuan Resistor adalah Ohm (simbol: Ω) yang merupakan satuan SI untuk resistansi listrik. Resitor mempunyai nilai resistansi (tahanan) tertentu yang dapat memproduksi tegangan listrik di antara kedua pin dimana nilai tegangan terhadap resistansi tersebut berbanding lurus dengan arus yang mengalir, berdasarkan persamaan hukum Ohm (V = I.R ).
6) Baterai

Baterai adalah perangkat yang terdiri dari satu atau lebih sel elektrokimia dengan koneksi eksternal yang disediakan untuk memberi daya pada perangkat listrik seperti senter, ponsel, dan mobil listrik. Ketika baterai memasok daya listrik, terminal positifnya adalah katode dan terminal negatifnya adalah anoda. Terminal bertanda negatif adalah sumber elektron yang akan mengalir melalui rangkaian listrik eksternal ke terminal positif. Ketika baterai dihubungkan ke beban listrik eksternal, reaksi redoks mengubah reaktan berenergi tinggi ke produk berenergi lebih rendah, dan perbedaan energi-bebas dikirim ke sirkuit eksternal sebagai energi listrik. Secara historis istilah "baterai" secara khusus mengacu pada perangkat yang terdiri dari beberapa sel, namun penggunaannya telah berkembang untuk memasukkan perangkat yang terdiri dari satu sel.
Prinsip operasi
Baterai mengubah energi kimia langsung menjadi energi listrik. Baterai terdiri dari sejumlah sel volta. Tiap sel terdiri dari 2 sel setengah yang terhubung seri melalui elektrolit konduktif yang berisi anion dan kation. Satu sel setengah termasuk elektrolit dan elektrode negatif, elektrode yang di mana anion berpindah; sel-setengah lainnya termasuk elektrolit dan elektrode positif di mana kation berpindah. Reaksi redoks akan mengisi ulang baterai. Kation akan tereduksi (elektron akan bertambah) di katode ketika pengisian, sedangkan anion akan teroksidasi (elektron hilang) di anode ketika pengisian. Ketika digunakan, proses ini dibalik. Elektrodanya tidak bersentuhan satu sama lain, tetapi terhubung via elektrolit. Beberapa sel menggunakan elektrolit yang berbeda untuk tiap sel setengah. Sebuah separator dapat membuat ion mengalir di antara sel-setengah dan bisa menghindari pencampuran elektrolit.
Arduino Uno adalah sebuah papan mikrokontroler berbasis ATmega328P yang digunakan untuk membuat berbagai proyek elektronik secara mudah dan terjangkau. Papan ini memiliki beberapa pin input dan output digital maupun analog yang memungkinkan pengguna membaca sensor serta mengontrol perangkat seperti motor, LED, atau relay. Arduino Uno dapat diprogram menggunakan Arduino IDE dengan bahasa pemrograman yang sederhana, sehingga cocok digunakan oleh pemula hingga profesional dalam merancang sistem otomatisasi, robotika, maupun perangkat IoT.

8) Sensor Flow Meter

Spesifikasi sensor pada sensor gas MQ-2 adalah sebagai berikut:


Output dari sensor adalah sinyal digital berbentuk pulsa square wave dengan level tegangan sekitar >4.5 V untuk HIGH dan <0.5 V untuk LOW (berdasarkan tabel spesifikasi). Artinya, pada kondisi tanpa aliran air, output akan tetap LOW atau menghasilkan pulsa sangat sedikit. Saat ada aliran, semakin besar laju aliran, semakin cepat rotor berputar, sehingga semakin banyak pulsa per detik yang keluar dari pin output. Rentang aliran yang dapat diukur adalah 10–300 L/menit dengan akurasi ±3%, dan tingkat duty cycle pulsa berkisar 50±10%. Sensor ini menggunakan tegangan kerja 5–18 V, tetapi operasi umum adalah 5V dengan konsumsi sekitar 15 mA, sehingga kompatibel untuk digunakan dengan mikrokontroler seperti Arduino.

Hall effect pada sensor flowmeter bekerja dengan memanfaatkan magnet kecil yang dipasang pada baling-baling atau impeller di dalam pipa; saat fluida mengalir, impeller berputar dan setiap putaran membawa magnet melewati elemen Hall di luar ruang aliran, sehingga medan magnet yang berubah-ubah menghasilkan pulsa tegangan Hall yang frekuensinya sebanding dengan kecepatan putaran impeller, dan dari frekuensi pulsa inilah laju aliran fluida dapat dihitung secara akurat tanpa kontak langsung antara rangkaian elektronik dan fluida.

Hall effect bekerja ketika arus listrik mengalir melalui suatu konduktor atau semikonduktor lalu dikenai medan magnet tegak lurus arah arus, sehingga gaya Lorentz mendorong elektron ke satu sisi bahan dan menimbulkan tegangan melintang yang disebut tegangan Hall; tegangan ini besarnya sebanding dengan kuat medan magnet sehingga dapat digunakan sebagai sinyal untuk mendeteksi posisi, kecepatan, atau arus listrik pada berbagai perangkat
9) Motor DC

Motor listrik DC atau DC Motor adalah suatu perangkat yang mengubah energi listrik menjadi energi kinetik atau gerakan (motion). Motor DC ini juga dapat disebut sebagai motor arus searah. Seperti namanya, DC Motor memiliki dua terminal dan memerlukan tegangan arus searah atau DC (Direct Current) untuk dapat menggerakannya.
Prinsip Kerja Motor DC
Terdapat dua bagian utama pada sebuah motor listrik DC, yaitu stator dan rotor. Stator adalah bagian motor yang tidak berputar, bagian yang statis ini terdiri dari rangka dan kumparan medan. Sedangkan rotor adalah bagian yang berputar, terdiri dari kumparan jangkar. Pada prinsipnya motor DC menggunakan fenomena elektromagnet untuk bergerak, ketika arus listrik diberikan ke kumparan, permukaan kumparan yang bersifat utara akan bergerak menghadap ke magnet yang berkutub selatan dan sebaliknya. Karena kutub utara dan selatan kumparan bertemu maka akan terjadi saling tarik menarik yang menyebabkan pergerakan kumparan berhenti.

Untuk menggerakannya lagi, tepat pada saat kutub kumparan berhadapan dengan kutub magnet, arah arus pada kumparan dibalik. Dengan demikian, kutub utara kumparan akan berubah menjadi kutub selatan dan kutub selatannya akan berubah menjadi kutub utara. Pada saat perubahan kutub tersebut terjadi, kutub selatan kumparan akan berhadap dengan kutub selatan magnet dan kutub utara kumparan akan berhadapan dengan kutub utara magnet. Karena kutubnya sama, maka akan terjadi tolak menolak sehingga kumparan bergerak memutar hingga utara kumparan berhadapan dengan selatan magnet dan selatan kumparan berhadapan dengan utara magnet. Pada saat ini, arus yang mengalir ke kumparan dibalik lagi dan kumparan akan berputar lagi karena adanya perubahan kutub. Siklus ini akan berulang-ulang hingga arus listrik pada kumparan diputuskan.
10) LED

LED merupakan sebuah komponen yang menghasilkan cahaya monokromatik ketika diberi tegangan. LED terbuat dari semikonduktor dan perbedaan warna yang dihasilkan disebabkan perbedaan bahan semikonduktor yang digunakan.
LED merupakan keluarga dari Dioda yang terbuat dari Semikonduktor. Cara kerjanya pun hampir sama dengan Dioda yang memiliki dua kutub yaitu kutub Positif (P) dan Kutub Negatif (N). LED hanya akan memancarkan cahaya apabila dialiri tegangan maju (bias forward) dari Anoda menuju ke Katoda.
LED terdiri dari sebuah chip semikonduktor yang di doping sehingga menciptakan junction P dan N. Yang dimaksud dengan proses doping dalam semikonduktor adalah proses untuk menambahkan ketidakmurnian (impurity) pada semikonduktor yang murni sehingga menghasilkan karakteristik kelistrikan yang diinginkan. Ketika LED dialiri tegangan maju atau bias forward yaitu dari Anoda (P) menuju ke Katoda (K), Kelebihan Elektron pada N-Type material akan berpindah ke wilayah yang kelebihan Hole (lubang) yaitu wilayah yang bermuatan positif (P-Type material). Saat Elektron berjumpa dengan Hole akan melepaskan photon dan memancarkan cahaya monokromatik (satu warna).

11) Buzzer

Buzzer adalah sebuah komponen elektronika yang berfungsi untuk mengubah getaran listrik menjadi getaran suara. Pada dasarnya prinsip kerja buzzer hampir sama dengan loud speaker, jadi buzzer juga terdiri dari kumparan yang terpasang pada diafragma dan kemudian kumparan tersebut dialiri arus sehingga menjadi elektromagnet, kumparan tadi akan tertarik ke dalam atau keluar, tergantung dari arah arus dan polaritas magnetnya, karena kumparan dipasang pada diafragma maka setiap gerakan kumparan akan menggerakkan diafragma secara bolak-balik sehingga membuat udara bergetar yang akan menghasilkan suara.
12) Relay

Relay merupakan komponen elektronika berupa saklar atau swirch elektrik yang dioperasikan secara listrik dan terdiri dari 2 bagian utama yaitu Elektromagnet (coil) dan mekanikal (seperangkat kontak Saklar/Switch). Komponen elektronika ini menggunakan prinsip elektromagnetik untuk menggerakan saklar sehingga dengan arus listrik yang kecil (low power) dapat menghantarkan listrik yang bertegangan lebih tinggi. Berikut adalah simbol dari komponen relay.
Pada dasarnya, Relay terdiri dari 4 komponen dasar yaitu :
• Electromagnet (Coil)
• Armature
• Switch Contact Point (Saklar)
• Spring

- Tegangan maksimum (DC): 150V.
- Konsumsi arus maksimum: 100mW.
- Tingkatan Resistansi/Tahanan : 10Ω sampai 100KΩ
- Puncak spektral: 540nm (ukuran gelombang cahaya)
- Waktu Respon Sensor : 20ms – 30ms.


.png)
4. Dasar Teori [kembali]

Resistor adalah komponen elektronika pasif yang memiliki nilai resistansi atau hambatan tertentu yang berfungsi untuk membatasi dan mengatur arus listrik dalam suatu rangkaian elektronika. Satuan Resistor adalah Ohm (simbol: Ω) yang merupakan satuan SI untuk resistansi listrik. Resitor mempunyai nilai resistansi (tahanan) tertentu yang dapat memproduksi tegangan listrik di antara kedua pin dimana nilai tegangan terhadap resistansi tersebut berbanding lurus dengan arus yang mengalir, berdasarkan persamaan hukum Ohm (V = I.R ).
Cara menghitung nilai resistor:
Tabel dibawah ini adalah warna-warna yang terdapat di tubuh resistor :

Perhitungan untuk resistor dengan 4 gelang warna :
• Masukkan angka langsung dari kode warna gelang ke-1 (pertama)
• Masukkan angka langsung dari kode warna gelang ke-2
• Masukkan Jumlah nol dari kode warna gelang ke-3 atau pangkatkan angka tersebut dengan 10 (10^n)
• Gelang ke 4 merupakan toleransi dari nilai resistor tersebut
Perhitungan untuk resistor dengan 5 gelang warna :
• Masukkan angka langsung dari kode warna gelang ke-1 (pertama)
• Masukkan angka langsung dari kode warna gelang ke-2
• Masukkan angka langsung dari kode warna gelang ke-3
• Masukkan Jumlah nol dari kode warna gelang ke-4 atau pangkatkan angka tersebut dengan 10 (10^n)
• Gelang ke 5 merupakan toleransi dari nilai resistor tersebut.
Rumus:


b. Transistor NPN
Transistor merupakan alat semikonduktor yang dapat digunakan sebagai penguat sinyal, pemutus atau penyambung sinyal, stabilisasi tegangan, dan fungsi lainnya. Transistor memiliki 3 kaki elektroda, yaitu basis, kolektor, dan emitor. Transistor ini diperumpamakan sebagai saklar, yaitu ketika kaki basis diberi arus, maka arus pada kolektor akan mengalir ke emiter yang disebut dengan kondisi ON. Sedangkan ketika kaki basis tidak diberi arus, maka tidak ada arus mengalir dari kolektor ke emitor yang disebut dengan kondisi OFF. Namun, jika arus yang diberikan pada kaki basis melebihi arus pada kaki kolektor atau arus pada kaki kolektor adalah nol (karena tegangan kaki kolektor sekitar 0,2 - 0,3 V), maka transistor akan mengalami cutoff (saklar tertutup).
Transistor adalah sebuah komponen di dalam elektronika yang diciptakan dari bahan-bahan semikonduktor dan memiliki tiga buah kaki. Masing-masing kaki disebut sebagai basis, kolektor, dan emitor.
• Emitor (E) memiliki fungsi untuk menghasilkan elektron atau muatan negatif.
• Kolektor (C) berperan sebagai saluran bagi muatan negatif untuk keluar dari dalam transistor.
• Basis (B) berguna untuk mengatur arah gerak muatan negatif yang keluar dari transistor melalui kolektor.



c. Baterai
Baterai adalah perangkat yang terdiri dari satu atau lebih sel elektrokimia dengan koneksi eksternal yang disediakan untuk memberi daya pada perangkat listrik seperti senter, ponsel, dan mobil listrik. Ketika baterai memasok daya listrik, terminal positifnya adalah katode dan terminal negatifnya adalah anoda. Terminal bertanda negatif adalah sumber elektron yang akan mengalir melalui rangkaian listrik eksternal ke terminal positif. Ketika baterai dihubungkan ke beban listrik eksternal, reaksi redoks mengubah reaktan berenergi tinggi ke produk berenergi lebih rendah, dan perbedaan energi-bebas dikirim ke sirkuit eksternal sebagai energi listrik. Secara historis istilah "baterai" secara khusus mengacu pada perangkat yang terdiri dari beberapa sel, namun penggunaannya telah berkembang untuk memasukkan perangkat yang terdiri dari satu sel.
Prinsip operasi
Baterai mengubah energi kimia langsung menjadi energi listrik. Baterai terdiri dari sejumlah sel volta. Tiap sel terdiri dari 2 sel setengah yang terhubung seri melalui elektrolit konduktif yang berisi anion dan kation. Satu sel setengah termasuk elektrolit dan elektrode negatif, elektrode yang di mana anion berpindah; sel-setengah lainnya termasuk elektrolit dan elektrode positif di mana kation berpindah. Reaksi redoks akan mengisi ulang baterai. Kation akan tereduksi (elektron akan bertambah) di katode ketika pengisian, sedangkan anion akan teroksidasi (elektron hilang) di anode ketika pengisian. Ketika digunakan, proses ini dibalik. Elektrodanya tidak bersentuhan satu sama lain, tetapi terhubung via elektrolit. Beberapa sel menggunakan elektrolit yang berbeda untuk tiap sel setengah. Sebuah separator dapat membuat ion mengalir di antara sel-setengah dan bisa menghindari pencampuran elektrolit.
d. Motor DC

Motor listrik DC atau DC Motor adalah suatu perangkat yang mengubah energi listrik menjadi energi kinetik atau gerakan (motion). Motor DC ini juga dapat disebut sebagai motor arus searah. Seperti namanya, DC Motor memiliki dua terminal dan memerlukan tegangan arus searah atau DC (Direct Current) untuk dapat menggerakannya.
Prinsip Kerja Motor DC
Terdapat dua bagian utama pada sebuah motor listrik DC, yaitu stator dan rotor. Stator adalah bagian motor yang tidak berputar, bagian yang statis ini terdiri dari rangka dan kumparan medan. Sedangkan rotor adalah bagian yang berputar, terdiri dari kumparan jangkar. Pada prinsipnya motor DC menggunakan fenomena elektromagnet untuk bergerak, ketika arus listrik diberikan ke kumparan, permukaan kumparan yang bersifat utara akan bergerak menghadap ke magnet yang berkutub selatan dan sebaliknya. Karena kutub utara dan selatan kumparan bertemu maka akan terjadi saling tarik menarik yang menyebabkan pergerakan kumparan berhenti.

Untuk menggerakannya lagi, tepat pada saat kutub kumparan berhadapan dengan kutub magnet, arah arus pada kumparan dibalik. Dengan demikian, kutub utara kumparan akan berubah menjadi kutub selatan dan kutub selatannya akan berubah menjadi kutub utara. Pada saat perubahan kutub tersebut terjadi, kutub selatan kumparan akan berhadap dengan kutub selatan magnet dan kutub utara kumparan akan berhadapan dengan kutub utara magnet. Karena kutubnya sama, maka akan terjadi tolak menolak sehingga kumparan bergerak memutar hingga utara kumparan berhadapan dengan selatan magnet dan selatan kumparan berhadapan dengan utara magnet. Pada saat ini, arus yang mengalir ke kumparan dibalik lagi dan kumparan akan berputar lagi karena adanya perubahan kutub. Siklus ini akan berulang-ulang hingga arus listrik pada kumparan diputuskan.
f. LED

LED merupakan sebuah komponen yang menghasilkan cahaya monokromatik ketika diberi tegangan. LED terbuat dari semikonduktor dan perbedaan warna yang dihasilkan disebabkan perbedaan bahan semikonduktor yang digunakan.
LED merupakan keluarga dari Dioda yang terbuat dari Semikonduktor. Cara kerjanya pun hampir sama dengan Dioda yang memiliki dua kutub yaitu kutub Positif (P) dan Kutub Negatif (N). LED hanya akan memancarkan cahaya apabila dialiri tegangan maju (bias forward) dari Anoda menuju ke Katoda.
LED terdiri dari sebuah chip semikonduktor yang di doping sehingga menciptakan junction P dan N. Yang dimaksud dengan proses doping dalam semikonduktor adalah proses untuk menambahkan ketidakmurnian (impurity) pada semikonduktor yang murni sehingga menghasilkan karakteristik kelistrikan yang diinginkan. Ketika LED dialiri tegangan maju atau bias forward yaitu dari Anoda (P) menuju ke Katoda (K), Kelebihan Elektron pada N-Type material akan berpindah ke wilayah yang kelebihan Hole (lubang) yaitu wilayah yang bermuatan positif (P-Type material). Saat Elektron berjumpa dengan Hole akan melepaskan photon dan memancarkan cahaya monokromatik (satu warna).

g. Sensor Flowmeter

Sensor flow meter YF-DN01 merupakan jenis turbine flow sensor yang digunakan untuk mengukur laju aliran fluida, khususnya air. Sensor ini banyak diaplikasikan pada sistem otomatisasi seperti dispenser air, pengukur konsumsi fluida, sistem irigasi otomatis, hingga monitoring debit air berbasis mikrokontroler ataupun IoT karena bentuknya sederhana, tahan lama, serta mudah diprogram.
1. Struktur Fisik Sensor
Sensor YF-DN01 umumnya terdiri dari tiga bagian utama:
-
Housing / body sensor
Terbuat dari plastik tahan air dengan ulir penghubung ke pipa atau selang. Diameter standar yang umum ditemui adalah DN10 atau DN20, disesuaikan dengan kebutuhan aliran.
-
Rotor (impeller) dengan magnet
Di dalam saluran sensor terdapat baling-baling kecil yang akan berputar ketika air mengalir. Pada salah satu bilah rotor tertanam magnet permanen kecil sebagai elemen pemicu sinyal.
-
Sensor Hall Effect
Dipasang di bagian atas ruang rotor. Ketika magnet pada baling-baling mendekati Hall sensor, medan magnet terdeteksi dan sensor menghasilkan sinyal pulsa.
Sensor YF-DN01 umumnya terdiri dari tiga bagian utama:
-
Housing / body sensor
Terbuat dari plastik tahan air dengan ulir penghubung ke pipa atau selang. Diameter standar yang umum ditemui adalah DN10 atau DN20, disesuaikan dengan kebutuhan aliran. -
Rotor (impeller) dengan magnet
Di dalam saluran sensor terdapat baling-baling kecil yang akan berputar ketika air mengalir. Pada salah satu bilah rotor tertanam magnet permanen kecil sebagai elemen pemicu sinyal. -
Sensor Hall Effect
Dipasang di bagian atas ruang rotor. Ketika magnet pada baling-baling mendekati Hall sensor, medan magnet terdeteksi dan sensor menghasilkan sinyal pulsa.
2. Prinsip Kerja
Prinsip kerja YF-DN01 didasarkan pada hubungan antara kecepatan aliran fluida dan kecepatan rotasi baling-baling. Prosesnya sebagai berikut:
-
Ketika air mengalir melalui sensor, tekanan aliran akan memutar baling-baling.
-
Magnet pada bilah rotor ikut berputar dan melewati area deteksi sensor Hall.
-
Setiap kali magnet lewat, Hall sensor berubah keadaan (on/off) dan menghasilkan pulsa logika digital.
-
Jumlah pulsa yang dihitung per satuan waktu sebanding dengan debit aliran air.
-
Pulsa ini diteruskan ke mikrokontroler (seperti Arduino) untuk dihitung dan dikonversi menjadi satuan aliran, misalnya liter/menit.
Produsen umumnya memberikan persamaan kalibrasi, misalnya:
Q (L/min) = k × F
di mana:
-
Q = debit aliran (liter per menit),
-
F = frekuensi pulsa (Hz),
-
k = konstanta kalibrasi sensor (sekitar 0.25 sampai 7.5 tergantung model).
Selain debit, total volume dapat diketahui dengan menjumlahkan pulsa seiring waktu:
Volume (L) = jumlah pulsa ÷ pulsa per liter
Prinsip kerja YF-DN01 didasarkan pada hubungan antara kecepatan aliran fluida dan kecepatan rotasi baling-baling. Prosesnya sebagai berikut:
-
Ketika air mengalir melalui sensor, tekanan aliran akan memutar baling-baling.
-
Magnet pada bilah rotor ikut berputar dan melewati area deteksi sensor Hall.
-
Setiap kali magnet lewat, Hall sensor berubah keadaan (on/off) dan menghasilkan pulsa logika digital.
-
Jumlah pulsa yang dihitung per satuan waktu sebanding dengan debit aliran air.
-
Pulsa ini diteruskan ke mikrokontroler (seperti Arduino) untuk dihitung dan dikonversi menjadi satuan aliran, misalnya liter/menit.
Produsen umumnya memberikan persamaan kalibrasi, misalnya:
Q (L/min) = k × F
di mana:
-
Q = debit aliran (liter per menit),
-
F = frekuensi pulsa (Hz),
-
k = konstanta kalibrasi sensor (sekitar 0.25 sampai 7.5 tergantung model).
Selain debit, total volume dapat diketahui dengan menjumlahkan pulsa seiring waktu:
Volume (L) = jumlah pulsa ÷ pulsa per liter
3. Sinyal Keluaran dan Pengolahan Data
Sensor ini bekerja pada tegangan 5 V dan menghasilkan sinyal digital berbentuk gelombang kotak. Pulsa dihitung menggunakan:
-
Interrupt (interrupt-on-change) pada mikrokontroler
-
Counter timer untuk menghitung frekuensi
-
Perhitungan volume total dilakukan dengan mengintegrasikan debit terhadap waktu, misalnya:
Volume = ∫ debit dt
Dalam sistem digital sederhana, volume dihitung dari jumlah total pulsa dibagi faktor kalibrasi tertentu.
Grafik respons dari flowmeter:

Sensor ini bekerja pada tegangan 5 V dan menghasilkan sinyal digital berbentuk gelombang kotak. Pulsa dihitung menggunakan:
-
Interrupt (interrupt-on-change) pada mikrokontroler
-
Counter timer untuk menghitung frekuensi
-
Perhitungan volume total dilakukan dengan mengintegrasikan debit terhadap waktu, misalnya:
Volume = ∫ debit dt
Dalam sistem digital sederhana, volume dihitung dari jumlah total pulsa dibagi faktor kalibrasi tertentu.
Grafik respons dari flowmeter:
4. Kelebihan dan Karakteristik
Sensor YF-DN01 memiliki beberapa kelebihan:
-
Biaya murah dan mudah digunakan
-
Keluaran digital sederhana, tidak membutuhkan ADC
-
Akurasi cukup baik untuk aplikasi monitoring harian
-
Konsumsi daya rendah
-
Dapat digunakan untuk kontrol otomatis berbasis mikrokontroler
Namun karena struktur mekanik, sensor ini dapat mengalami penyimpangan akibat:
-
Busa atau udara dalam aliran
-
Kotoran yang menghambat rotor
-
Ketidakteraturan tekanan aliran
Sehingga pemeliharaan kebersihan saluran menjadi penting untuk menjaga keakuratan.
Sensor YF-DN01 memiliki beberapa kelebihan:
-
Biaya murah dan mudah digunakan
-
Keluaran digital sederhana, tidak membutuhkan ADC
-
Akurasi cukup baik untuk aplikasi monitoring harian
-
Konsumsi daya rendah
-
Dapat digunakan untuk kontrol otomatis berbasis mikrokontroler
Namun karena struktur mekanik, sensor ini dapat mengalami penyimpangan akibat:
-
Busa atau udara dalam aliran
-
Kotoran yang menghambat rotor
-
Ketidakteraturan tekanan aliran
Sehingga pemeliharaan kebersihan saluran menjadi penting untuk menjaga keakuratan.
5. Aplikasi Sensor
Flow meter YF-DN01 banyak digunakan pada:
-
Sistem kontrol pompa otomatis
-
Dispenser atau kompor air
-
Sistem irigasi tanaman
-
Monitoring debit air pada smart home atau IoT
-
Pengukuran konsumsi cairan pada eksperimen laboratorium
h. Float Switch
Float switch adalah sensor level cairan berbasis pelampung yang digunakan untuk mendeteksi ketinggian fluida dalam suatu wadah, tangki, ataupun sistem penampung. Sensor ini banyak dipakai dalam sistem otomatisasi air, pengendali pompa, alarm level cairan, hingga aplikasi industri dan rumah tangga karena prinsip kerjanya sederhana, biaya murah, dan reliabilitas tinggi.
Flow meter YF-DN01 banyak digunakan pada:
-
Sistem kontrol pompa otomatis
-
Dispenser atau kompor air
-
Sistem irigasi tanaman
-
Monitoring debit air pada smart home atau IoT
-
Pengukuran konsumsi cairan pada eksperimen laboratorium
Secara umum, float switch terdiri dari:
-
Pelampung (float body): terbuat dari plastik atau stainless steel yang berisi udara sehingga dapat mengapung mengikuti permukaan air.
-
Tuas atau batang pemandu: menjadi jalur pergerakan pelampung secara vertikal.
-
Elemen kontak listrik (reed switch atau microswitch): terletak di bagian dalam tabung atau wadah, yang akan aktif ketika pelampung berubah posisi.
Pada banyak model, sebuah magnet kecil ditanam di bagian pelampung. Ketika magnet mendekati reed switch (saklar kontak sensitif magnet), kontak akan tertutup atau terbuka.
Prinsip kerja float switch didasarkan pada perubahan posisi pelampung akibat naik-turunnya permukaan cairan. Saat level air tinggi, pelampung ikut naik ke atas dan menggerakkan mekanisme saklar sehingga rangkaian berubah status (ON atau OFF). Sebaliknya, ketika air turun, pelampung turun dan saklar beralih ke keadaan semula.
Dengan kata lain, sensor ini bekerja layaknya saklar otomatis yang dipicu oleh gaya apung (buoyancy). Status kontak ini kemudian dipakai untuk menyalakan atau mematikan pompa, membuka katup solenoid, atau sebagai input monitoring mikrokontroler.
Secara umum, float switch terdiri dari:
-
Pelampung (float body): terbuat dari plastik atau stainless steel yang berisi udara sehingga dapat mengapung mengikuti permukaan air.
-
Tuas atau batang pemandu: menjadi jalur pergerakan pelampung secara vertikal.
-
Elemen kontak listrik (reed switch atau microswitch): terletak di bagian dalam tabung atau wadah, yang akan aktif ketika pelampung berubah posisi.
Pada banyak model, sebuah magnet kecil ditanam di bagian pelampung. Ketika magnet mendekati reed switch (saklar kontak sensitif magnet), kontak akan tertutup atau terbuka.
Prinsip kerja float switch didasarkan pada perubahan posisi pelampung akibat naik-turunnya permukaan cairan. Saat level air tinggi, pelampung ikut naik ke atas dan menggerakkan mekanisme saklar sehingga rangkaian berubah status (ON atau OFF). Sebaliknya, ketika air turun, pelampung turun dan saklar beralih ke keadaan semula.
Dengan kata lain, sensor ini bekerja layaknya saklar otomatis yang dipicu oleh gaya apung (buoyancy). Status kontak ini kemudian dipakai untuk menyalakan atau mematikan pompa, membuka katup solenoid, atau sebagai input monitoring mikrokontroler.
-
Jenis keluaran: kontak digital (ON/OFF)
-
Tegangan kerja sesuai rangkaian kontrol (5 V mikrokontroler atau 12–220 V pada sistem relay)
-
Sensitivitas posisi ditentukan oleh desain reed switch dan jarak magnet
-
Tahan terhadap air, beberapa model juga tahan kimia
Selain bentuk tabung vertikal (vertical type), ada pula tipe pelampung gantung kabel (cable float switch) yang menggunakan ball-switch di dalam pelampung besar.
i. pH sensor
Sensor pH merupakan perangkat pengukur tingkat keasaman atau kebasaan suatu larutan. Parameter pH menunjukkan konsentrasi ion hidrogen (H⁺) dalam larutan, dinyatakan dalam skala logaritmik dari 0 hingga 14, di mana nilai 7 bersifat netral, nilai di bawah 7 menandakan kondisi asam, dan di atas 7 menunjukkan kondisi basa. Pengukuran pH menjadi penting dalam berbagai bidang seperti pertanian, pengolahan makanan, lingkungan, biologi, kimia, dan pengolahan air.
Skala pH diturunkan dari persamaan:
pH = –log [H⁺]
Artinya semakin banyak ion hidrogen dalam larutan, semakin rendah nilai pH-nya. Karena sifat logaritmik, perubahan satu unit pH mewakili perubahan sepuluh kali lipat konsentrasi ion H⁺.
Sensor pH umum dikenal sebagai elektroda gelas pH, terdiri dari:
-
Electrode sensing (glass electrode): elektroda khusus yang sensitif terhadap ion H⁺. Permukaannya berupa membran kaca tipis yang menimbulkan tegangan ketika terkena larutan dengan aktivitas ion H⁺ tertentu.
-
Electrode referensi: elektroda pembanding dengan potensial stabil (biasanya Ag/AgCl dalam larutan KCl), berada dalam ruang tertutup yang terhubung ke larutan melalui junction atau pori semipermeabel.
Kedua elektroda ini membentuk sistem pengukuran diferensial. Tegangan keluaran sensor berkisar sekitar –414 mV hingga +414 mV pada rentang pH 0–14.
Prinsip kerja sensor pH mengikuti hukum Nernst, di mana membran kaca menimbulkan potensial listrik sebagai fungsi aktivitas ion hidrogen di permukaan elektroda. Ketika elektroda sensing dicelupkan dalam larutan, permukaan membrannya berinteraksi dengan ion H⁺ dan menghasilkan tegangan tertentu. Tegangan ini dibandingkan dengan elektroda referensi sehingga menghasilkan sinyal output.
Persamaan tegangan sensor ideal:
E = E₀ + (2.303 RT / nF) × pH
Pada suhu 25°C, sensitivitas teorinya sekitar 59 mV per perubahan 1 satuan pH.
Dengan demikian, nilai pH dihitung dari perbandingan antara tegangan yang dihasilkan elektroda dan karakteristik sensor yang diperoleh melalui kalibrasi.
Karena tegangan keluaran sangat kecil dan impedansinya tinggi (hingga ratusan megaohm), sistem pembacaan pH memerlukan:
-
Penguat impedansi tinggi (instrumentation amplifier / elektrometer),
-
Filter untuk mengurangi noise,
-
Kalibrasi dua titik (pH 4 dan pH 7 atau pH 7 dan pH 10),
-
Kompensasi suhu karena sensitivitas tergantung suhu.
Unit pH meter komersial biasanya mengintegrasikan sensor dan rangkaian pengolahan sinyal.
berikut merupakan grafik respon sensor pH:

Grafik tersebut menunjukkan hubungan antara tegangan keluaran sensor pH (dalam satuan milivolt) dengan nilai pH larutan. Kurva tampak menurun dari kiri ke kanan, yang berarti semakin tinggi tegangan positif yang dihasilkan sensor, semakin rendah nilai pH atau semakin asam larutan tersebut. Sebaliknya, semakin negatif tegangan keluarannya, semakin tinggi nilai pH yang menunjukkan larutan bersifat basa. Bentuk kurva yang sedikit melengkung mencerminkan kenyataan bahwa karakteristik sensor pH tidak sepenuhnya linier, sehingga diperlukan pemodelan atau kalibrasi untuk mengubah tegangan menjadi nilai pH yang akurat. Grafik ini pada dasarnya menggambarkan prinsip kerja sensor pH, yaitu mengubah fenomena kimia berupa konsentrasi ion hidrogen menjadi sinyal listrik yang dapat dibaca sistem elektronik, serta menjelaskan bagaimana sensor digunakan dalam monitoring kualitas air seperti pada sistem hidroponik atau pengolahan air.
j. LDR
LDR (Light Dependent Resistor) merupakan salah satu komponen resistor yang nilai resistansinya akan berubah-ubah sesuai dengan intensitas cahaya yang mengenai sensor ini. LDR juga dapat digunakan sebagai sensor cahaya. Perlu diketahui bahwa nilai resistansi dari sensor ini sangat bergantung pada intensitas cahaya. Semakin banyak cahaya yang mengenainya, maka akan semakin menurun nilai resistansinya. Sebaliknya jika semakin sedikit cahaya yang mengenai sensor (gelap), maka nilai hambatannya akan menjadi semakin besar sehingga arus listrik yang mengalir akan terhambat.
LDR di proteus

Grafik respon
Grafik memperlihatkan bahwa semakin tinggi intensitas cahaya (lux), semakin rendah resistansi LDR. Pada area cahaya sangat rendah (sekitar 0.1–1 lux), resistansi LDR dapat mencapai mega-ohm, menandakan sensor hampir “gelap total”. Saat iluminasi meningkat ke area sedang (10–100 lux), resistansinya turun ke puluhan hingga ribuan ohm, menunjukkan LDR semakin menghantarkan arus. Pada iluminasi tinggi (100–1000 lux), resistansi bisa turun di bawah 1 kΩ, yang menandakan sensor menerima banyak cahaya. Garis tebal merah menunjukkan salah satu karakteristik tipikal LDR: pola penurunan resistansi yang non-linear, tetapi konsisten mengikuti tren eksponensial menurun. Secara keseluruhan, grafik ini menggambarkan bahwa output resistansi LDR sangat sensitif terhadap perubahan cahaya dan bekerja berdasarkan sifat semiconductor photoconductivity—lebih banyak cahaya berarti lebih banyak elektron bebas yang menurunkan resistansinya.
-
Jenis keluaran: kontak digital (ON/OFF)
-
Tegangan kerja sesuai rangkaian kontrol (5 V mikrokontroler atau 12–220 V pada sistem relay)
-
Sensitivitas posisi ditentukan oleh desain reed switch dan jarak magnet
-
Tahan terhadap air, beberapa model juga tahan kimia
Selain bentuk tabung vertikal (vertical type), ada pula tipe pelampung gantung kabel (cable float switch) yang menggunakan ball-switch di dalam pelampung besar.
i. pH sensor
Skala pH diturunkan dari persamaan:
pH = –log [H⁺]
Artinya semakin banyak ion hidrogen dalam larutan, semakin rendah nilai pH-nya. Karena sifat logaritmik, perubahan satu unit pH mewakili perubahan sepuluh kali lipat konsentrasi ion H⁺.
Sensor pH umum dikenal sebagai elektroda gelas pH, terdiri dari:
-
Electrode sensing (glass electrode): elektroda khusus yang sensitif terhadap ion H⁺. Permukaannya berupa membran kaca tipis yang menimbulkan tegangan ketika terkena larutan dengan aktivitas ion H⁺ tertentu.
-
Electrode referensi: elektroda pembanding dengan potensial stabil (biasanya Ag/AgCl dalam larutan KCl), berada dalam ruang tertutup yang terhubung ke larutan melalui junction atau pori semipermeabel.
Kedua elektroda ini membentuk sistem pengukuran diferensial. Tegangan keluaran sensor berkisar sekitar –414 mV hingga +414 mV pada rentang pH 0–14.
Prinsip kerja sensor pH mengikuti hukum Nernst, di mana membran kaca menimbulkan potensial listrik sebagai fungsi aktivitas ion hidrogen di permukaan elektroda. Ketika elektroda sensing dicelupkan dalam larutan, permukaan membrannya berinteraksi dengan ion H⁺ dan menghasilkan tegangan tertentu. Tegangan ini dibandingkan dengan elektroda referensi sehingga menghasilkan sinyal output.
Persamaan tegangan sensor ideal:
E = E₀ + (2.303 RT / nF) × pH
Pada suhu 25°C, sensitivitas teorinya sekitar 59 mV per perubahan 1 satuan pH.
Dengan demikian, nilai pH dihitung dari perbandingan antara tegangan yang dihasilkan elektroda dan karakteristik sensor yang diperoleh melalui kalibrasi.
Karena tegangan keluaran sangat kecil dan impedansinya tinggi (hingga ratusan megaohm), sistem pembacaan pH memerlukan:
-
Penguat impedansi tinggi (instrumentation amplifier / elektrometer),
-
Filter untuk mengurangi noise,
-
Kalibrasi dua titik (pH 4 dan pH 7 atau pH 7 dan pH 10),
-
Kompensasi suhu karena sensitivitas tergantung suhu.
Unit pH meter komersial biasanya mengintegrasikan sensor dan rangkaian pengolahan sinyal.
berikut merupakan grafik respon sensor pH:
Grafik tersebut menunjukkan hubungan antara tegangan keluaran sensor pH (dalam satuan milivolt) dengan nilai pH larutan. Kurva tampak menurun dari kiri ke kanan, yang berarti semakin tinggi tegangan positif yang dihasilkan sensor, semakin rendah nilai pH atau semakin asam larutan tersebut. Sebaliknya, semakin negatif tegangan keluarannya, semakin tinggi nilai pH yang menunjukkan larutan bersifat basa. Bentuk kurva yang sedikit melengkung mencerminkan kenyataan bahwa karakteristik sensor pH tidak sepenuhnya linier, sehingga diperlukan pemodelan atau kalibrasi untuk mengubah tegangan menjadi nilai pH yang akurat. Grafik ini pada dasarnya menggambarkan prinsip kerja sensor pH, yaitu mengubah fenomena kimia berupa konsentrasi ion hidrogen menjadi sinyal listrik yang dapat dibaca sistem elektronik, serta menjelaskan bagaimana sensor digunakan dalam monitoring kualitas air seperti pada sistem hidroponik atau pengolahan air.
j. LDR
h. Buzzer
Buzzer adalah sebuah komponen elektronika yang berfungsi untuk mengubah getaran listrik menjadi getaran suara. Pada dasarnya prinsip kerja buzzer hampir sama dengan loud speaker, jadi buzzer juga terdiri dari kumparan yang terpasang pada diafragma dan kemudian kumparan tersebut dialiri arus sehingga menjadi elektromagnet, kumparan tadi akan tertarik ke dalam atau keluar, tergantung dari arah arus dan polaritas magnetnya, karena kumparan dipasang pada diafragma maka setiap gerakan kumparan akan menggerakkan diafragma secara bolak-balik sehingga membuat udara bergetar yang akan menghasilkan suara.
i. Relay

Relay merupakan komponen elektronika berupa saklar atau swirch elektrik yang dioperasikan secara listrik dan terdiri dari 2 bagian utama yaitu Elektromagnet (coil) dan mekanikal (seperangkat kontak Saklar/Switch). Komponen elektronika ini menggunakan prinsip elektromagnetik untuk menggerakan saklar sehingga dengan arus listrik yang kecil (low power) dapat menghantarkan listrik yang bertegangan lebih tinggi. Berikut adalah simbol dari komponen relay.
Pada dasarnya, Relay terdiri dari 4 komponen dasar yaitu :
• Electromagnet (Coil)
• Armature
• Switch Contact Point (Saklar)
• Spring
5. Percobaan [kembali]
a. Prosedur Percobaan [kembali]
- siapkan komponen yang dibutuhkan
- letakkansemua komponen sesuai dengan gambar dibawah
- selanjutnya hubungkan ke motor
- letakan juga sensor suara,sensor pir ,sensor infrared, sensor vibration, sensor flame, sensor tekanan
- setelah semua komponen tersusun dan terhubung,
- play kan simulasinya
- jika benar maka simulasi bisa dibuat applikasinya
b. Gambar Rangkaian dan Prinsip Kerja [kembali]

rangkaian monitoring dan kontrol hidroponik pakcoy yang dikendalikan oleh STM32 Bluepill sebagai pusat pengolahan data dan pengendali aktuator. Sistem ini dirancang untuk memantau kondisi pH larutan nutrisi, ketersediaan air, debit aliran air, serta kondisi pencahayaan, kemudian melakukan tindakan otomatis agar kondisi lingkungan tetap sesuai dengan kebutuhan tanaman pakcoy.
Pada bagian pengukuran dan pengendalian pH, rangkaian menggunakan sensor pH yang terhubung ke pin ADC STM32 Bluepill. Sensor ini membaca nilai keasaman larutan nutrisi secara kontinu. Nilai pH yang terbaca dibandingkan dengan set point yang ditentukan, yaitu pada rentang pH 6,5–7 (netral). Jika pH larutan terdeteksi lebih besar dari set point (kondisi basa), STM32 akan mengaktifkan motor pompa cairan asam melalui rangkaian driver/relay sehingga cairan asam dialirkan ke larutan nutrisi untuk menurunkan pH. Sebaliknya, jika pH terdeteksi lebih kecil dari set point (kondisi asam), maka motor pompa cairan basa akan diaktifkan untuk menaikkan pH hingga kembali mendekati kondisi netral. Dengan demikian, terdapat dua motor khusus untuk pengaturan pH, masing-masing untuk cairan asam dan cairan basa.
Untuk menjaga ketersediaan air dan nutrisi, rangkaian dilengkapi sensor float switch yang dipasang pada tangki utama. Float switch berfungsi mendeteksi ketinggian air di dalam tangki. Ketika level air menurun akibat diserap oleh tanaman atau karena penguapan, float switch akan mengirimkan sinyal ke STM32. Berdasarkan sinyal tersebut, STM32 akan mengaktifkan motor pompa air untuk menyuplai air ke sistem hidroponik sehingga tanaman pakcoy tetap mendapatkan air dan nutrisi yang cukup.
Pada jalur keluaran air yang dikendalikan oleh float switch, rangkaian dipasangkan sensor flowmeter. Sensor ini berfungsi untuk mengukur kecepatan atau debit aliran air yang mengalir menuju tanaman. Flowmeter menghasilkan pulsa yang sebanding dengan laju aliran air, kemudian pulsa tersebut dihitung oleh STM32 untuk memperoleh nilai debit aliran. Informasi debit air ini ditampilkan pada LCD, sehingga pengguna dapat memantau apakah aliran air bekerja dengan normal atau tidak.
Rangkaian juga dilengkapi sensor LDR (Light Dependent Resistor) yang berfungsi untuk mendeteksi kondisi cahaya lingkungan, apakah dalam keadaan siang atau malam. LDR terhubung ke STM32 melalui rangkaian pembagi tegangan sehingga perubahan intensitas cahaya dapat dibaca oleh ADC. Jika LDR mendeteksi tidak adanya cahaya atau intensitas cahaya rendah (kondisi malam), STM32 akan mengaktifkan lampu grow light melalui rangkaian driver sebagai pengganti sinar matahari. Sebaliknya, ketika cahaya alami mencukupi, lampu grow light akan dimatikan secara otomatis.
Sistem ini menggunakan dua buah tangki air, yaitu tangki utama dan tangki cadangan. Tangki utama berfungsi untuk menyuplai air dan nutrisi ke tanaman pakcoy secara terus-menerus. Tangki cadangan berperan sebagai backup, yang akan digunakan ketika float switch mendeteksi bahwa air pada tangki utama berada di bawah batas minimum. Dengan konfigurasi ini, kontinuitas suplai air ke tanaman tetap terjaga meskipun terjadi kekurangan air pada tangki utama.
Secara keseluruhan, rangkaian ini mengendalikan empat motor pompa, yaitu motor pompa cairan pH asam, motor pompa cairan pH basa, motor pompa air dari tangki utama, dan motor pompa air dari tangki cadangan. Integrasi sensor pH, float switch, flowmeter, dan LDR dengan STM32 Bluepill menjadikan rangkaian ini mampu melakukan monitoring dan kontrol hidroponik pakcoy secara otomatis, terukur, dan efisien.
6. Download File [kembali]
- File Simulasi Rangkaian [download]
- Video simulasi rangkaian [download]
- Video 2 simulasi rangkaian [download]
- LIbrary Infrared Sensor [download]
- Library Flame Sensor [download]
- Library Vibration Sensor [download]
- Library Sound Sensor [download]
- Datasheet Potensiometer [download]
- Datasheet Resistor [download]
- Datasheet Dioda [download]
- Datasheet Transistor [download]
- Datasheet OP-AMP [download]
- Datasheet Relay [download]
- Datasheet Motor DC [download]
- Datasheet Baterai [download]
- Datasheet Flame Sensor [download]
- Datasheet Vibration Sensor [download]
- Datasheet LDR Sensor [download]
- Datasheet Sound Sensor [download]
- Datasheet Infrared Sensor [download]
- Datasheet Sensor Tekanan [download]















